Prise en main de MySQL
Présentation de MySQL
![]()
MySQL server est un serveur de base de données (BDD = base de données).
On parle généralement de SGBD pour système de gestion de base de données (abr. SGBD).
Il peut contenir plusieurs bases de données.
Une base de données peut contenir plusieurs tables.
Interfaces
Plusieurs interfaces permettant d'interagir avec MySQL server existent.
Il y a tout d'abord d'un côté :
interface textuelle (aussi nommée console mysql)
utilisable en ligne de commande (en passant des paramètres)
utilisable de manière interactive (l'invite
mysql>apparait)
Affichage de l'aide de l'interface en ligne de commande:
$ mysql --help

- interfaces graphiques
- MySQL workbench
- phpMyAdmin
MySQL workbench
MySQL workbench est une interface graphique permettant de facilement interagir avec le serveur MySQL server. Il s'agit d'une interface type "client lourd" (à installer sur un ordinateur).
La page de démarrage de MySQL workbench se présente ainsi:

Elle permet de :
- se connecter à une base de données existante ou créer une base de données
- modéliser une base de données
- administrer un (ou plusieurs) serveurs MySQL
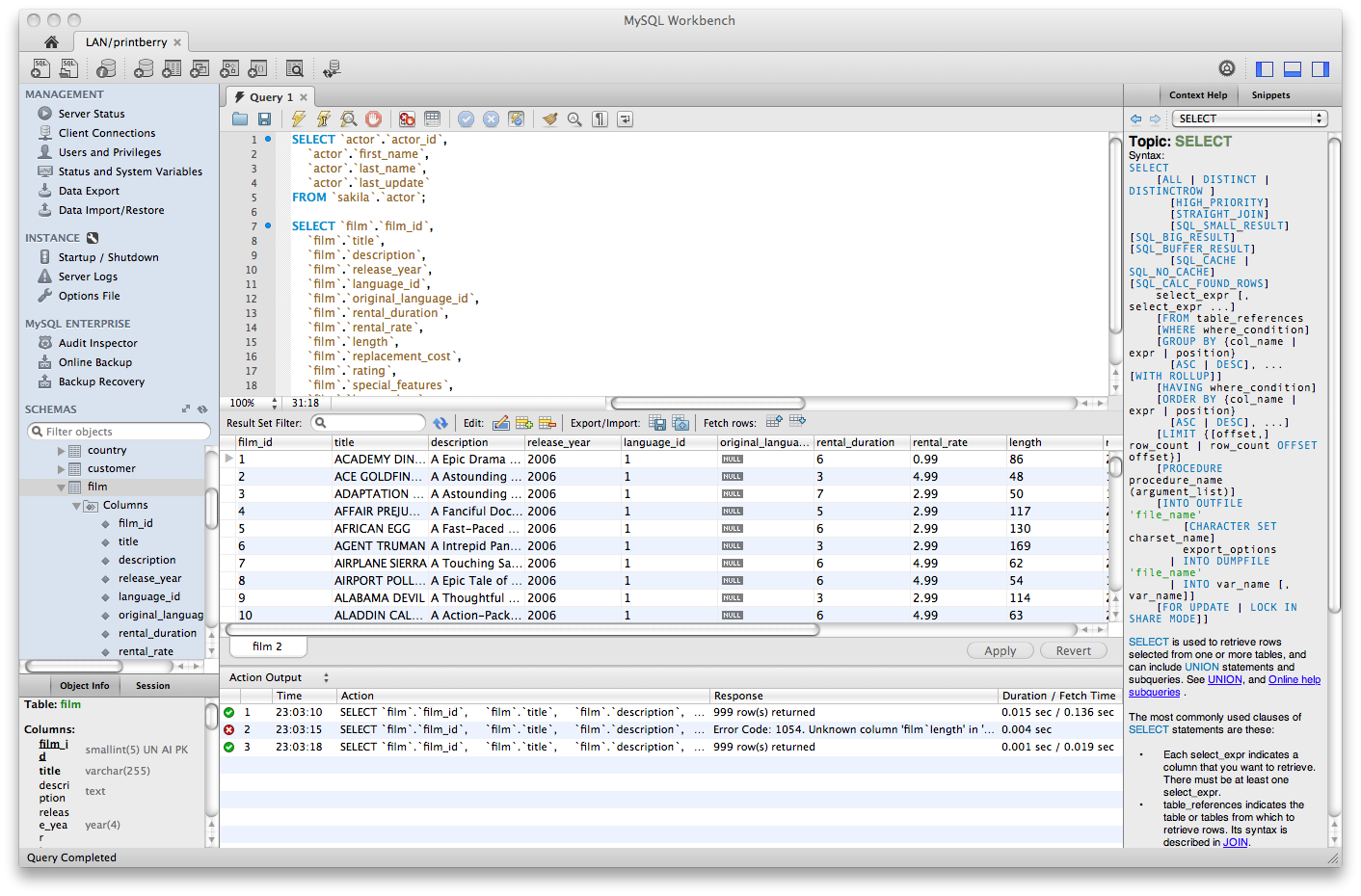
L'interface d'édition d'une base de données se présente ainsi :
phpMyAdmin
phpMyAdmin http://www.phpmyadmin.net/ est généralement une solution utilisée dans le cadre de l'administration de base de données MySQL accessible via un navigateur.
![]()
Il s'agit d'une interface web.

Quelques examples d'opérations sur une base de données
Les bases de données relationnelles utilisent la syntaxe SQL (Structured Query Language).
SQL (sigle de Structured Query Language, en français langage de requête structurée) est un langage informatique normalisé servant à exploiter des bases de données relationnelles.
La partie langage de manipulation des données de SQL permet de rechercher, d'ajouter, de modifier ou de supprimer des données dans les bases de données relationnelles.
Création d'une base de données
Création d'une base de données nommée meteo.
CREATE DATABASE IF NOT EXISTS `meteo` DEFAULT CHARACTER SET utf8;
Si la base de données existe déjà elle n'est pas recréée.
L'encodage des caractères utilisé est utf8 (Unicode UTF-8).
Choisir la base de données par défaut
Lorsque des requêtes SQL sont exécutées, elles le sont sur une base de données déterminée (base par défaut). On peut définir cette base par défaut à l'aide de l'instruction :
USE `meteo`;
Notions d'utilisateur et de droits
Il est possible de créer divers utilisateurs.
CREATE USER 'testuser'@'localhost' IDENTIFIED BY 'test623';
Pour ce nouvel utilisateur il est possible de modifier l'accès (aucun accès, lecture seule, modification)
GRANT ALL ON meteo.* TO 'testuser'@'localhost';
Il est possible (mais cela n'est pas recommandé) d'utiliser
l'utilisateur root (qui a tous les droits) sur les différentes bases
et sur le serveur de base de données.
Suppression d'une base de données
DROP DATABASE `meteo`;

DROP DATABASE `meteo` IF NOT EXISTS;
Création d'une table dans une base de données
CREATE TABLE `data`;
on peut aussi utiliser
CREATE TABLE IF NOT EXISTS `data`;
cela évite de déclencher une erreur si la table existe déjà.
Suppression d'une table
DROP TABLE `data`;
Effacement d'une table
TRUNCATE TABLE `data`;
permet de supprimer toutes les données d’une table sans supprimer la table en elle-même
DELETE FROM table_name WHERE some_column=some_value;
permet de supprimer les données d’une table selon certaines conditions
Il ne faut pas confondre:
- Supprimer une table
DROP TABLE - Effacer le contenu d'une table
TRUNCATEouDELETE
La suppression d'une table (DROP) supprime le contenu de la table et sa structure. L'effacement d'une table ne supprime "que" (!!!) les données... pas la structure de la table.
Insertion d'éléments dans une table
INSERT INTO `meteo.data` VALUES ('2015-06-03 09:00:00', 22.1);
Remarque à propos des timestamps:
Il est souvent préférable de stocker les timestamps en heure UTC afin d'éviter les problèmes de changement d'heure (été / hiver), et non l'heure locale.
Certaines bases de données (comme PosGreSQL) prennent en charge les timestamps avec timezone ('2015-06-03 11:00:00+02')
Voir : http://stackoverflow.com/questions/19023978/should-mysql-have-its-timezone-set-to-utc
Le plus simple est d'éditer le fichier my.cnf ou my.ini dans
C:\Program Files\MySQL Server x.y\ ou
C:\ProgramData\MySQL Server x.y\ et y placer dans la section
[mysqld]
default_time_zone='+00:00'
ou
timezone='UTC'
On peut vérifier que la configuration du timezone en demandant l'heure actuelle à l'aide de la requête suivante :
SELECT CURRENT_TIMESTAMP();
On doit voir l'heure actuelle (en UTC) donc avec :
- 1 heure de décalage l'hiver avec l'heure de Paris
- 2 heures de décalage l'été avec l'heure de Paris
Affichage d'éléments
SELECT * FROM `data` WHERE `Timestamp`>'2015-06-01' LIMIT 10;
Remarque : les backquotes (`) ne sont pas nécessaires mais sont généralement ajouté par MySQL workbench. Ainsi, la requête suivant est tout aussi valide.
SELECT * FROM data WHERE Timestamp>'2015-06-01' LIMIT 10;
Il est possible de classer selon l'ordre d'une (ou plusieurs) colonnes :
SELECT * FROM data WHERE Timestamp>2015-06-01 ORDER BY Timestamp DESC LIMIT 10;
DESCsignifie descending (ordre décroissant)ASCsignifie ascending (ordre croissant)
On ne peut afficher que certaines colonnes (COLONNE1 et COLONNE2
ici):
SELECT COLONNE1, COLONNE2 FROM data;
On peut compter le nombre d'éléments :
SELECT COUNT(*) FROM data;
Notion de jointures
Une base de données peut-être constituée de plusieurs tables.
Les jointures en SQL permettent d’associer plusieurs tables dans une même requête.
Cela permet d’exploiter la puissance des bases de données relationnelles pour obtenir des résultats qui combinent les données de plusieurs tables de manière efficace.
INNER JOIN: jointure interne pour retourner les enregistrements quand la condition est vrai dans les 2 tables. C’est l’une des jointures les plus communes.CROSS JOIN: jointure croisée permettant de faire le produit cartésien de 2 tables. En d’autres mots, permet de joindre chaque lignes d’une table avec chaque lignes d’une seconde table. Attention, le nombre de résultats est en général très élevé.LEFT JOIN(ouLEFT OUTER JOIN) : jointure externe pour retourner tous les enregistrements de la table de gauche (LEFT = gauche) même si la condition n’est pas vérifié dans l’autre table.RIGHT JOIN(ouRIGHT OUTER JOIN) : jointure externe pour retourner tous les enregistrements de la table de droite (RIGHT = droite) même si la condition n’est pas vérifié dans l’autre table.FULL JOIN(ouFULL OUTER JOIN) : jointure externe pour retourner les résultats quand la condition est vrai dans au moins une des 2 tables.SELF JOIN: permet d’effectuer une jointure d’une table avec elle-même comme si c’était une autre table.NATURAL JOIN: jointure naturelle entre 2 tables s’il y a au moins une colonne qui porte le même nom entre les 2 tables SQLUNION JOIN: jointure d’union
En savoir plus :
Dumps SQL
Le mot "dump" est issu du terme anglais dump signifiant "dépôt, décharge, déverser massivement".
On appelle dump, une sauvegarde de base de données à un instant donné de l'état de ses bases.
Dans le cas des bases de données on parle indifféremment de dump ou de sauvegarde, que l'on conserve ou non la définition de la structure des données.
Dans la majorité des cas des bases utilisant le langage SQL, la sauvegarde est constituée d'un ensemble d'instructions d’insertion au format SQL.
Il existe également avec certaines bases, comme MySQL par exemple, des logs binaires, sauvegardes (ou dump) des actions déroulées plutôt que des données présentes dans la base.
Restaurer une base de données = Exécuter un dump
MySQL workbench
Dans MySQL workbench, pour restaurer une base de données, il suffit d'aller dans le menu
Fichier / Exécuter un script SQL...
ou en anglais
File / Run SQL script...
Une boîte de dialogue permet de définir le dump (fichier .sql) à
importer.
Attention ! Il ne faut pas confondre avec :
Fichier / Ouvir un script SQL...
ou en anglais
File / Open SQL script...
En effet, en cas de dump de grande taille, ouvrir un script SQL dans l'éditeur de MySQL workbench au lieu de simplement l'exécuter (sans l'éditer) risque d'être très long (au risque de bloquer le bon fonctionnement du système d'exploitation).
Remarque : il peut être nécessaire de rafraichir l'affichage des bases de données et de tables pour mettre à jour l'affichage de MySQL workbench (Refresh All).
Ligne de commande mysql
L'importation d'un dump SQL peut également se faire en ligne de commande.
Il suffit d'ouvrir un interpréteur de commande (bash sous Linux ou Mac
OS X ou en appuyant sur les touches WINDOWS + r et en tapant cmd).
$ mysql -u root meteo < dump.sql
Il est nécessaire d'être dans le répertoire de MySQL ou que le binaire
mysql soit dans le PATH (PATH est la variable système utilisée par le
système d'exploitation pour localiser les fichiers exécutables
indispensables depuis la ligne de commande ou la fenêtre de terminal).
Console mysql
L'importation d'un dump SQL peut également se faire via l'interface
(interactive) mysql console.
$ mysql -u root
L'invite de commande de mysql console apparait (mysql>) et on peut
taper :
mysql> use DATABASE_NAME;
mysql> source chemin/vers/dump.sql;
On peut quitter l'invite de commande de mysql console en tapant
mysql> exit
ou tapant CTRL + d
Sauvegarder une base de données
MySQL workbench
Il est possible de Sauvegarder une base de données via l'interface graphique de MySQL workbench via le menu :
Server / Data Export
Ligne de commande mysqldump
Sauvegarder une base de données via la ligne de commande mysqldump
peut se faire via :
$ mysqldump -u root -p password > dump.sql
Sauvegarder une base de données grâce à la ligne de commande mysqldump
est très utile car cela peut être facilement automatisé (notamment à
l'aide de tâches planifiés sous Windows ou à l'aide de la crontab sous
Linux, Unix, ...)
Cron : https://fr.wikipedia.org/wiki/Cron Planifier une tâche / schedule task : http://windows.microsoft.com/fr-fr/windows/schedule-task
Connexion MySQL / Python
Afin de faire du traitement de données en Python depuis des données stockées dans une base de données MySQL il est nécessaire d'installer un connecteur.
Le connecteur par défaut est téléchargeable à l'adresse suivante:
https://dev.mysql.com/downloads/connector/python/
Connecteurs
On suppose que le serveur de bases de données MySQL est installée avec les paramètres suivants:
- utilisateur :
root - mot de passe :
root - hôte :
localhost(ou l'adresse IP127.0.0.1) - port :
3306 - base de données par défaut :
meteo
Remarque : dans une véritable configuration de "production", il faut être soucieux des paramètres de sécurité (définition d'un mot de passe fort, restriction de l'accès à la base...). L'accès à des données non protégées peut être problématique.
Soit le dictionnaire suivant contenant les paramètres de connexion à la base de données :
db_config = {
'user': 'root',
'password': 'root',
'host': '127.0.0.1',
'port': '3306',
'database': 'meteo'
}
Obtenir une connexion à la BDD (objet cnx) avec mysql.connector
>>> import mysql.connector
>>> cnx = mysql.connector.connect(host=db_config['host'], database=db_config['database'], user=db_config['user'], password=db_config['password'])
>>> cursor = cnx.cursor()
>>> sql_query = "SELECT * FROM data LIMIT 10;"
>>> n = cursor.execute(sql_query)
>>> print("n:", n)
>>> data = cursor.fetchall()
>>> print("data:", data)
>>> cursor.close()
>>> cnx.close()
On obtient le résultat dans un tuple de tuple (de 10 éléments).
n: 10
data: ((datetime.datetime(2011, 3, 7, 17, 30, 3), 56.0, 91.0, 131.0, 2.3, 3.6, 6.4, 10.3, 51.4, 1006.5, 22.83, 57250.0, 0.0, 0.0, 0.0, 0.0, 37.2, 0.0, 9.2, 15.0, 15.3, 3.503), ..., (datetime.datetime(2011, 3, 7, 18, 20, 3), 76.0, 96.0, 142.0, 2.8, 3.8, 4.8, 8.5, 57.1, 1006.8, 22.83, 57250.0, 0.0, 0.0, 0.0, 0.0, 37.2, 0.0, 6.6, 15.0, 15.2, 3.504))
Obtenir une connexion à la BDD (objet cnx) avec pymysql
>>> import pymysql
>>> cnx = pymysql.connect(host=db_config['host'], db=db_config['database'], user=db_config['user'], passwd=db_config['password'])
>>> cursor = cnx.cursor()
>>> sql_query = "SELECT * FROM data LIMIT 10;"
>>> n = cursor.execute(sql_query)
>>> print(n)
>>> data = cursor.fetchall()
>>> print(data)
>>> cnx.close()
SQLAlchemy
SQLAlchemy est un ORM (Object-relational mapping ou en français Mapping objet-relationnel), il s'agit d'une couche d'abstraction supplémentaire qui permet de sauvegarder dans une base de données relationnelle des objets sans avoir à se soucier de leur sérialisation.
Un ORM permet en outre à l'aide d'un même code d'utiliser différents type de bases de données comme :
- MySQL https://www.mysql.fr/
- MariaDB (fork de MySQL) https://mariadb.org/
- PostgreSQL http://www.postgresql.org/
- Oracle Database http://www.oracle.com/fr/database
- Microsoft SQL Server https://www.microsoft.com/fr-fr/server-cloud/products/sql-server/
- SQLite https://www.sqlite.org/
Le code suivant permet par exemple de créer un engine (moteur)
permettant (si les dépendances sont bien installées) d'exécuter une
requête SQL sur une base de données MySQL à partir d'un URI (Uniform
Resource Identifier).
from sqlalchemy import create_engine
# db_uri = 'dialect+driver://username:password@host:port/database'
# db_uri = 'mysql://root:root@localhost:3306/meteo' # default
# db_uri = 'mysql+mysqldb://root:root@localhost:3306/meteo' # mysql-python
db_uri = 'mysql+mysqlconnector://root:root@localhost:3306/meteo' # MySQL-connector-python
# db_uri = 'mysql+oursql://root:root@localhost:3306/meteo' # OurSQL
engine = create_engine(db_uri, echo=True)
cnx = engine.connect()
sql_query = "SELECT * FROM data"
result = cnx.execute(sql_query)
Connexion MySQL / Pandas
Il est possible d'exécuter une requête SQL à l'aide de Pandas.
import pandas as pd
df = pd.read_sql(sql_query, con)
sql_queryest soit :- le nom d'une table
- une requête SQL (
SELECT * FROM table WHERE ...habituellement) conest un paramètre connexion à la base de données. Il peut s'agir soit :- d'un objet de connexion tel que renvoyé par
mysql.connectorou parpymysqlcommecnx - d'un
enginerenvoyé par l'ORM SQLAlchemy - de l'URI (Uniform Resource Identifier) vers une base de données
comme
db_uri
voir la documentation complète sur http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_sql.html
On obtient alors dans la variable df un DataFrame permettant d'accéder
à nos données désormais en mémoire.
Attention ! Lorsque le volume de données à récupérer est trop important, il devient nécessaire de :
- faire des requêtes plus sélective (en ne récupérant pas l'ensemble des colonnes mais que les colonnes utiles pour la suite du traitement, en ne récupérant pas l'ensemble des enregistrements (lignes) mais uniquement celles nécessaire pour l'analyse...)
- récupérer les données par morceaux (chunk by chunk http://pandas.pydata.org/pandas-docs/dev/io.html#iterating-through-files-chunk-by-chunk) et concaténer les DataFrames (voir http://pandas.pydata.org/pandas-docs/stable/merging.html#concatenating-objects)
- utiliser une bibliothèque dédiée comme Blaze https://github.com/ContinuumIO/blaze qui évite au maximum de rapatrier l'ensemble des données en mémoire (out-of-core algorithm).
- paralléliser les traitements avec une bibliothèque dédiée comme https://dask.org/.