Introduction à Python
![]()
Historique
créé en 1989 par Guido van Rossum
version 2.0 en 2000
- version courante 2.7.10
version 3.0 en 2008
- version courante 3.4.3
- plus cohérent, "propre", meilleur support d'Unicode (encodage des caractères)
recommandation : choisir Python3 pour les nouveaux projets
- sauf dépendance incontournable à une librairie pas encore migrée en Python 3
Caractéristiques
- facile à apprendre
- structures de données de haut niveau
- orienté objet
- interprété
- extensible
- Open Source
- disponible et portable "tel quel" sur toutes les plateformes
- pratique plus que puriste
- accent sur la lisibilité
- typage fort, mais non déclaré
- puissant : coeur minimaliste, mais bibliothèque très étendue (UI, web, fichiers, bases de données, manipulation de texte...)
Popularité
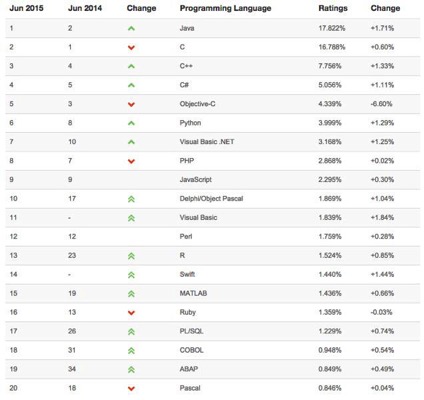
Index Tiobe
Index Tiobe http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html
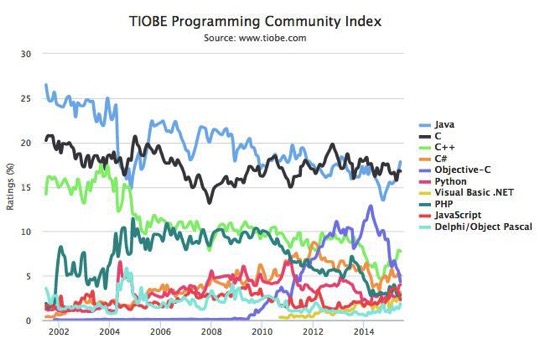
Index PyPL
Index PyPL :
http://pypl.github.io/PYPL.html
basé sur les recherches "tutorial langage" sur Google
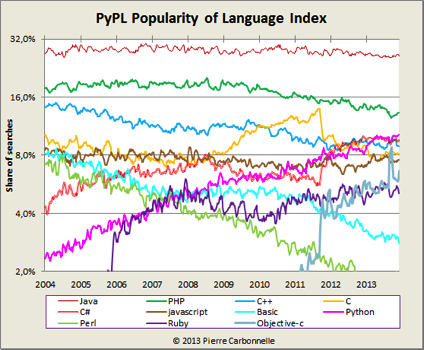
GitHub
Projets créés sur Github https://github.com/ en 2013
Rank Language # Repositories Created
1 JavaScript 264131
2 Ruby 218812
3 Java 157618
4 PHP 114384
5 Python 95002
6 C++ 78327
7 C 67706
8 Objective-C 36344
9 C# 32170
10 Shell 28561
Autres
Largement utilisé par Google (dont Guido van Rossum était salarié jusqu'en 2012, maintenant chez DropBox), sur Youtube
Mercurial (gestion de version) est écrit en Python.
Web frameworks :
- Zope http://www.zope.org/
- Django https://www.djangoproject.com/
- Flask http://flask.pocoo.org/
Success stories : http://www.python.org/about/success/
Installation
On peut aller sur le site http://python.org pour trouver un installeur Python. Mais notre objectif est ici d'utiliser Python dans un cadre scientifique donc un certain nombre de bibliothèque sont nécessaires (SciPy Stack http://www.scipy.org/stackspec.html).
Dans un tel cadre, il est préférable d'utiliser une distribution scientifique de Python.
Sinon par exemple :
- Enthought Python http://www.enthought.com/
- Anaconda Python - Continuum Analytics http://continuum.io/
- Pythonxy http://code.google.com/p/pythonxy/
Nous utiliserons pour notre part la distribution Anaconda Python de Continuum Analytics.
![]()
![]()
La distribution doit être installée avec la version 3 de Python.
http://continuum.io/downloads#py34
L'installation crée une commande python dans l'invite de commande, qui lance l'interpréteur interactif
Il est aussi possible d'utiliser au choix
IPython
![]()
Il s'agit d'un interpréteur beaucoup plus évolué que l'interpréteur de base. Il permet de :
- compléter les expressions saisies à l'aide de la touche
TAB - accéder à la documentation du code
?variable... - d'exécuter du code présent dans le presse papier à l'aide de
%paste
Le projet IPython a évolué et est devenu indépendant du langage Python. Il se nomme également Jupyter et peut être utilisé pour de nombreux autres langages (Julia, Haskell, Ruby, R, F#...).
![]()
Spyder
Spyder est un environnement interactif de développement de Python. Il s'agit d'un éditeur de code source avec coloration syntaxique. Il propose l'introspection de code et des fonctions d'analyse. Il comporte également un éditeur de tableau NumPy, un éditeur de dictionnaires, une console Python, ...
Notepad++
Il s'agit d'un éditeur de texte généraliste.
![]()
Une fois sauvé, le code saisi dans l'éditeur devra être exécuté en lançant
une console (CTRL+r puis cmd) et en tapant :
C:\ cd chemin\vers\repertoire\du\script
C:\ python.exe nom_fichier.py
La touche TAB permet généralement de compléter la saisie.
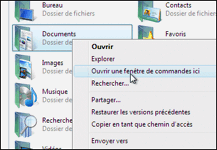
A partir de Windows 7, il est possible d'ouvir une console dans un répertoire donné (majuscule + clic droit dans l'explorateur Windows sur le répertoire souhaité).
Autres
Visual Studio Code https://code.visualstudio.com/
un éditeur de code extensible développé par Microsoft pour Windows, Linux et OS X
IEP (Interactive Editor for Python) http://www.iep-project.org/
inclu dans la distribution scientifique de Python Pyzo http://www.pyzo.org/
https://wiki.python.org/moin/IntegratedDevelopmentEnvironments
Ressources
- la documentation Python : http://docs.python.org/3/
- forums / newsgroup : comp.lang.python, comp.lang.python.fr
- StackOverflow http://stackoverflow.com/
- Python Package Index http://pypi.python.org/
- The Python Cookbook http://chimera.labs.oreilly.com/books/1230000000393
Commentaires
Introduits par #
# this is the first comment
SPAM = 1 # and this is the second comment
# ... and now a third!
STRING = "# This is not a comment.
Les commentaires doivent aider la compréhension du code.
Définition de noms (variables)
On stocke le nombre (entier) 20 dans la variable `width (se lit de droite à gauche).
>>> width = 20
On augmente le contenu de la variable width de 10 et on stocke le résultat dans
la variable width.
>>> width += 10
>>> width
30
Equivalent à :
>>> width = 20
>>> width = width + 10
>>> width
30
Autre
>>> height = 5 * 9
>>> x = y = z = 0
>>> tax = 0.125
>>> ht = 100.50
>>> ttc = ht * (1+tax)
>>> round(ttc, 2)
113,06
Il est possible d'assigner plusieurs variables à l'aide d'une seule instruction.
>>> a, b = 5, 4
La variable a contient le nombre entier 5.
La variable b contient le nombre entier 4.
Types int, float et bool
On trouve des nombres entiers (type int comme integer)
>>> type(width)
int
et des nombres "flottants" (type float comme floating)
>>> type(tax)
float
Le type bool (booléen ou boolean)
>>> b_result = width > 10
>>> b_result
True
>>> not b_result
False
>>> type(b_result)
bool
On peut comparer le type d'une variable à un type donné
>>> isinstance(width, int)
True
>>> isinstance(width, float)
False
>>> isinstance(tax, int)
False
>>> isinstance(tax, float)
True
On peut comparer le type d'une variable à plusieurs types donnés
>>> isinstance(tax, (int, float)) # tax est de type int ou float
True
équivalent
>>> isinstance(tax, int) or isinstance(tax, float)
True
or est opérateur logique (OU)
Documentation - Docstring
Lorsque l'on utilise l'interpréteur IPython, il est possible d'afficher la
documentation d'une fonction à l'aide de ?. Cela affiche la docstring d'une fonction,
d'un objet...
>>> ?type
Type: type
String form: <class 'type'>
Namespace: Python builtin
Docstring:
type(object) -> the object's type
type(name, bases, dict) -> a new type
Chaînes de caractères
Délimitation
Utilise ' ou "
'spam eggs'
"spam eggs"
"doesn't"
'"Yes," he said.'
Le symbole \ pour échappement
'doesn\'t'
"\"Yes,\" he said."
'"Isn\'t," she said.'
Continuation de chaînes
Le symbole \ pour continuer une ligne
hello = "This is a rather long string containing\n\
several lines of text just as you would do in C.\n\
Note that whitespace at the beginning of the line is\
significant."
Le symbole """ pour des chaînes sur plusieurs lignes
print("""
Usage: thingy [OPTIONS]
-h Display this usage message
-H hostname Hostname to connect to
""")
Mode par défaut et mode brut
Mode par défaut :
>>> word = 'a\nb'
>>> print(word)
a
b
Mode brut (r = raw) :
>>> word = r'a\nb'
>>> print(word)
a\nb
Concaténation et duplication
Concaténation par +, duplication par *
>>> word = 'Help' + 'A'
>>> word
'HelpA'
>>> '<' + word*5 + '>'
'<HelpAHelpAHelpAHelpAHelpA>'
Accès à un caractère par index
+---+---+---+---+---+
| H | e | l | p | A |
+---+---+---+---+---+
0 1 2 3 4
-5 -4 -3 -2 -1
>>> word[4]
'A'
>>> word[-2]
'p'
Remarque : Python utilise des index commençant par 0 (comme le langage C mais contrairement au Pascal, à MATLAB, à Julia qui utilise le nombre 1 comme 1er indice).
Tranches
+---+---+---+---+---+
| H | e | l | p | A |
+---+---+---+---+---+
0 1 2 3 4 5
-5 -4 -3 -2 -1
>>> word[0:2]
'He'
>>> word[2:4]
'lp'
>>> word[:2]
'He'
>>> word[3:]
'pA'
Test d'appartenance
>>> s = 'abcde'
>>> 'a' in s
True
>>> 'b' not in s
False
>>> 'x' in s
False
Immutabilité
Les chaînes sont immutables c'est à dire qu'il n'est pas possible de modifier un caractère sans reconstruire la chaîne.
>>> word = 'HelpA'
>>> word[1]='a'
TypeError: 'str' object does not support item assignment
Longueur d'une chaîne
>>> word = 'anticonstitutionnellement'
>>> len(word)
25
Définition
>>> a = ['spam', 'eggs', 100, 1234]
>>> a
['spam', 'eggs', 100, 1234]
Accès par index ou par tranche
>>> a[0]
'spam'
>>> a[3]
1234
>>> a[-2]
100
>>> a[1:-1]
['eggs', 100]
Concaténation et duplication
Concaténation par +, duplication par *
>>> 3*a[:3] + ['Boo!']
['spam', 'eggs', 100, 'spam', 'eggs', 100, 'spam', 'eggs', 100, 'Boo!']
Affectation et clonage
>>> a = [0, 1]
>>> b = a # les noms 'a' et 'b' sont liés au même objet
>>> b[0] = 9 # toute modification sur b modifie aussi a
>>> a
[9, 1]
>>> b = a[:] # clonage : création d'un objet différent de a
>>> b[0] = 1
>>> a
[9, 1]
Mutatibilité
Les listes sont mutables c'est à dire qu'il est possible de modifier un élément de la liste.
>>> a
['spam', 'eggs', 100, 1234]
>>> a[2] = a[2] + 23
>>> a
['spam', 'eggs', 123, 1234]
Longueur
Longueur d'une liste par len
>>> a = ['a', 'b', 'c', 'd']
>>> len(a)
4
Transformation
Transformer une listes de chaînes en une seule chaîne : méthode join appliquée au séparateur
>>> a = ["O rage", "ô désespoir", "ô vieillesse ennemie"]
>>> ' ! '.join(a)
'O rage ! ô désespoir ! ô vieillesse ennemie'
Ici le séparateur est la chaîne de caractères ' ! '.
Découpage
Découper une chaîne de caractères en éléments d'une liste
>>> s = "La cigale et la fourmi"
>>> s.split()
['La', 'cigale', 'et', 'la', 'fourmi']
>>> s = "et un ! et deux ! et trois zéros !"
>>> s.split('!')
['et un ', ' et deux ', ' et trois zéros ', '']
Listes imbriquées
Une liste peut contenir d'autres listes:
>>> q = [2, 3]
>>> p = [1, q, 4]
>>> p
[1, [2, 3], 4]
>>> len(p)
3
>>> p[1]
[2, 3]
>>> p[1][0]
2
Ajout
Ajout d'un élément à la fin d'une liste par append
>>> q = [2, 3]
>>> q.append('xtra')
>>> q
[2, 3, 'xtra']
Insertion
Insertion d'un élément à une position donnée par insert
>>> q.insert(1, 'new')
>>> q
[2, 'new', 3, 'xtra']
Tuples
Comme une liste, mais immuable
>>> t = (1, 2, 'a')
>>> t[1]
2
>>> t[2] = 'b'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
Premiers pas en programmation
La fonction print
>>> i = 256*256
>>> print('La valeur de i est', i)
La valeur de i est 65536
Conditions : if, elif, else
>>> x = input("Saisissez un nombre entier : ") # "raw_input"
>>> x = int(x) # conversion de la chaîne de caractères en entier
Saisissez un nombre entier : 42
>>> if x < 0:
... x = 0
... print('Nombre négatif changé en zéro')
... elif x == 0:
... print('Zéro')
... elif x == 1:
... print('Un')
... else:
... print('Plusieurs')
...
More
Remarque:
- indentation
- utiliser de préférence 4 espaces (plutôt que tabulation
- pas de "switch / case" comme en C
Boucle for
Un des outils les plus puissants de Python
>>> a = ['cat', 'window', 'snake']
>>> for x in a:
... print(x, len(x))
...
cat 3
window 6
snake 5
L'itération par for ... in permet de manipuler les valeurscontenues dans la liste plutôt que les *index.
Boucle while
>>> mot_de_passe = 'python'
>>> while(True):
... mot_saisi = input("Saisissez votre mot de passe: ")
... if mot_saisi == mot_de_passe:
... break
Saisissez votre mot de passe: pas bon
Saisissez votre mot de passe: toujours pas
Saisissez votre mot de passe: python
La fonction range
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
Syntaxe : range(stop) ou range(start, stop[, step]) (le paramètre step est optionnel).
Remarque: une version moins "Pythonesque" (plus proche du C) de l'exemple sur la boucle For
>>> a = ['cat', 'window', 'snake']
>>> for i in range(len(a)):
print(a[i], len(a[i]))
Itérateurs
range et Python 2
>>> range(5)
[0, 1, 2, 3, 4]
En Python 2, range renvoie une liste
range et Python 3
>>> range(5)
range(0, 5)
En Python 3, range renvoie un itérateur
Dans for x in A, A est un itérateur
Certaines fonctions prennent un itérateur comme argument, par exemple list
>>> list(range(5))
[0, 1, 2, 3, 4]
continue
>>> for num in range(2, 6):
... if num % 2 == 0:
... continue
... print("Nombre impair", num)
Nombre impair 3
Nombre impair 5
L'opérateur modulo % permet de facilement distinguer nombres pairs et impairs.
break et else dans une boucle
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0: # x divise n
... print(n, '=', x, '*', n//x)
... break
... else: # nombre premier
... print(n, 'est un nombre premier')
...
2 est un nombre premier
3 est un nombre premier
4 = 2 * 2
5 est un nombre premier
6 = 2 * 3
7 est un nombre premier
8 = 2 * 4
9 = 3 * 3
Le bloc après else est exécuté si on ne sort pas de la boucle par un break
Fonctions
Définition
>>> def soustraire(x, y):
... """soustraire y à x"""
... return x - y
>>> soustraire(5, 3)
2
Notion d'arguments et de valeur de retour
La fonction soustrairepossède ici deux arguments (obligatoire) x et y.
return permet de définir une (ou plusieurs) valeur(s) de retour.
Remarque: En l'absence de return dans la définition d'une fonction, la valeur de retour de cette fonction est None.
Arguments par défaut
Définition d'arguments par défaut (keyword arguments)
>>> def f(x, y=4):
... return x+y
...
>>> f(2)
6
>>> f(2,3)
5
Remarque: L'argument par défaut est calculé au moment de la définition de la fonction (pas au moment de l'appel de la fonction).
>>> i = 5
>>> def f(y=i):
... print(y)
...
>>> i = 6
>>> f()
5
Il n'est évalué qu'une seule fois.
>>> def f(a, L=[]):
... L.append(a)
... return L
...
>>> f(1)
[1]
>>> f(2)
[1,2]
Appel de la fonction
>>> def f(x, y):
... return x - y
...
On peut appeler une fonction avec des arguments
>>> f(1, 2)
-1
ou des mots-clés (keyword arguments)
>>> f(y=6, x=2)
-4
On trouve bien -4 et pas 4 !
On ne peut pas donner deux fois le même argument
>>> f(3, x=8)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: f() got multiple values for argument 'x'
*args et **kwargs
Une fonction peut être appelée avec un nombre indéterminé d'arguments
>>> def f(*args):
... print(args) # tuple
...
>>> f(1, 2, 'a')
(1, 2, 'a')
et un nombre indéterminé de mots-clés
>>> def f(**kw):
... print(kw) # dictionnaire
...
>>> f(x=0, y='a')
{'x':0, 'y':'a'}
Appel de fonction par dépliage
Appel de fonction par "dépliage de tuple"
>>> def f(x, y):
... return x+y
...
>>> t = (3, 5)
>>> f(*t)
8
Appel de fonction par "dépliage de dictionnaire"
>>> d = {'x':3, 'y':5}
>>> f(**d)
8
Listes
Création par list comprehensions (listes en extension)
>>> [ x for x in range(5) ]
[0, 1, 2, 3, 4]
>>> [ x*2 for x in range(5) ]
[0, 2, 4, 6, 8]
>>> [ x*2 for x in range(5) if x != 3 ]
[0, 2, 4, 8]
Imbrication de list comprehensions
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]
...
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
Suppression d'éléments
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]
Tuples
C'est la virgule qui crée un tuple, pas la parenthèse
>>> t = 1,2
>>> t
(1,2)
>>> x = (1)
>>> x
1
>>> x=(1,)
>>> x
(1,)
Ensembles (set)
Création
Comme une liste, mais sans duplication ni ordre
>>> panier = {'pomme', 'orange', 'pomme', 'poire', 'orange', 'banane'}
>>> panier # les doublons sont éliminés
{'banane', 'poire', 'pomme', 'orange'} # Python 3
>>> 'orange' in panier
True
>>> 'abricot' in panier
False
ou création par set comprehensions
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
Ajout
>>> panier.add('abricot')
>>> panier
{'banane', 'poire', 'abricot', 'pomme', 'orange'}
Intersection d'ensembles
>>> couleurs = {'bleu','jaune','orange'}
>>> panier & couleurs
{'orange'}
Union
>>> panier | couleurs
{'jaune', 'poire', 'banane', 'abricot', 'bleu', 'pomme', 'orange'}
Dictionnaires (dict)
Création
Associe une clé (immuable : chaîne, entier, tuple...) à une valeur
>>> tel = {'jack': 4098, 'sape': 4139} # création
>>> tel['guido'] = 4127 # nouvel élément
>>> tel
{'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> tel['jack'] # accès par clé
4098
>>> tel['jack'] = 4099 # changement de valeur
>>> del tel['sape'] # suppression
>>> tel['irv'] = 4127
>>> tel
{'guido': 4127, 'irv': 4127, 'jack': 4099}
>>> 'guido' in tel # test d'appartenance (clé)
True
>>> 'jack' not in tel
False
Clés
tel.keys() renvoie :
- la liste des clés en Python 2
- un itérateur sur la liste des clés en Python 3
Même chose pour tel.values() (valeurs) et tel.items() (tuples clé,valeur)
>>> for key, value in tel.items():
... print(key,"'s number is ", value) # Python version > 2.4
...
jack 's number is 4099
irv 's number is 4127
guido 's number is 4127
Itération
Itérer sur un dictionnaire c'est itérer sur ses clés
>>> for key in tel:
... print(key)
...
irv
guido
jack
contrairement aux listes qui itèrent sur les valeurs
>>> for value in [1,'a']:
... print(value)
...
1
'a'
Autres techniques de construction de dictionnaires
Construction par dict
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
ou par dict comprehensions
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
Itérations
enumerate
enumerate pour itérer sur le tuple (rang, valeur)
>>> for i, x in enumerate(['bordeaux', 'rennes']):
... print(i,x)
...
0 bordeaux
1 rennes
Plus "pythonique" (ou "pythonesque") que :
>>> lst = ['bordeaux', 'rennes']
>>> for i in range(len(lst)): # ouh le débutant !
... print(i,lst[i])
...
0 bordeaux
1 rennes
ça c'est plutôt la manière d'itérer dans un tableau que l'on utiliserait en C
zip
zip pour itérer sur plusieurs séquences à la fois
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your '+q+'? It is '+a)
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
Affectation multiple
Pour affecter plusieurs variables à la fois
>>> a, b = 4, 3
>>> a
4
>>> b
3
itère avec range et affecte les valeurs
>>> a,b,c = range(3)
>>> c
2
>>> a,b = {3:9,10:20}
>>> b
10
Il faut le même nombre de valeurs des deux côtés sinon l'exception ValueError est levée !
>>> a, b, c = range(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 3)
Scripts
Avec Python, il est possible de travailler de deux manières:
- en mode intéractif (avec l'interpréteur Python)
- en mode script
Dans ce dernier cas, il faut enregistrer le programme dans un fichier monscript.py (par exemple)
for i in range(1):
print(i)
Dans l'invite de commandes, aller dans le répertoire de script.py et exécuter
C:\Users\login> cd repertoire_contenant_script
C:\Users\login> python monscript.py
0
1
2
3
4
Modules
Créer un module
Sauvegarde dans un fichier fibo.py
def fib(n):
"""Affiche les valeurs de la suite de Fibonacci series jusqu'à n"""
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a+b
print()
def fib2(n):
"""Retourne les valeurs de la suite de Fibonacci series jusqu'à n"""
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a+b
return result
Le module fibo contient deux fonctions fib et fib2.
Importer un module
import pour importer un module
>>> import fibo
>>> fibo.fib(1000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
>>> fibo.fib2(100)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
>>> fibo.__name__
'fibo'
from X import n1, n2... pour importer des noms d'un module
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
from X import * pour importer tous les noms du module (attention aux conflits de noms !).
>>> from fibo import *
>>> fib2(100)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
C'est généralement une mauvaise pratique d'importer toutes les noms d'un même module à cause de problème de conflits de noms.
Recherche d'un module par son nom :
- dans la librairie standard
- puis dans le répertoire courant
Packages
Pour structurer des librairies qui contiennent plusieurs modules
Organisation en répertoires qui contiennent un fichier __init__.py
sound/
__init__.py
formats/
__init__.py
wavread.py
...
effects/
__init__.py
echo.py
import sound
import sound.formats
from sound.formats import wavread
La fonction dir()
pour inspecter les noms définis par un module
>>> import fibo, sys
>>> dir(fibo)
['__name__', 'fib', 'fib2']
Sans arguments : liste les noms définis dans le module courant
>>> a = [1, 2, 3, 4, 5]
>>> import fibo
>>> fib = fibo.fib
>>> dir()
['__builtins__', '__doc__', '__file__', '__name__', 'a', 'fib', 'fibo']
Visualiser le code d'un module
On peut facilement accéder au code source d'un module (la lecture du code créeer par d'autre est souvent instructive).
On peut afficher le chemin du fichier d'un module via :
>>> import module
>>> module.__file__
On peut alors ouvrir ce fichier dans un éditeur de texte afin de mieux comprendre ce module
Si vous utilisez IPython, vous pouvez même faire :
!votreediteur module.__file__
Cela ouvre votre éditeur de texte avec le fichier du module en question.
str.format() avec {}
Permet de mettre en forme une chaîne de caractères selon certains paramètres
Exemple:
>>> print('We are the {} who say "{}!"'.format('knights', 'Ni'))
We are the knights who say "Ni!"
Les séquences {} sont remplacées par les arguments de format
On peut spécifier le rang de l'argument à insérer :
>>> print('{0} and {1}'.format('spam', 'eggs'))
spam and eggs
>>> print('{1} and {0}'.format('spam', 'eggs'))
eggs and spam
str.format() avec {keyword}
On peut spécifier des mots-clés
>>> print('This {food} is {adjective}.'.format(
... food='spam', adjective='absolutely horrible'))
This spam is absolutely horrible.
et mélanger rang et mots-clés
>>> print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',
... other='Georg'))
The story of Bill, Manfred, and Georg.
str.format() et nombre de décimales
On peut spécifier le nombre de décimales à utiliser
>>> import math
>>> print 'The value of PI is approximately {0:.3f}.'.format(math.pi)
The value of PI is approximately 3.142
et le nombre minimal de caractères
>>> table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
>>> for name, phone in table.items():
... print '{0:10} ==> {1:10d}'.format(name, phone)
...
Jack ==> 4098
Dcab ==> 7678
Sjoerd ==> 4127
Erreurs et exceptions
Python distingue :
les erreurs : détectées dans la phase d'analyse du programme
- erreurs de syntaxe
- erreur d'indentation
les exceptions : surviennent pendant l'exécution d'un programme
SyntaxError
`SyntaxError`
>>> while True print 'Hello world'
File "<stdin>", line 1, in ?
while True print 'Hello world'
^
SyntaxError: invalid syntax
IndentationError
`IndentationError`
>>> for i in range(5):
... print i
File "<stdin>", line 2
print i
^
IndentationError: expected an indented block
Exception
>>> 10 * (1/0)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ZeroDivisionError: integer division or modulo by zero
Il est interdit de diviser par `0`.
>>> 4 + spam*3
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: name 'spam' is not defined
La variable `spam` n'est pas définie.
>>> '2' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: cannot concatenate 'str' and 'int' objects
Une chaîne de caractères et un entier ne peuvent pas être concaténés.
Gestion des exceptions
try ... except pour gérer des exceptions
>>> while True:
... try:
... x = int(raw_input("Veuillez entrer un nombre: "))
... break
... except ValueError:
... print("Ce n'est pas un nombre valide. Recommencer...")
...
Si une instruction du bloc try déclenche une exception, on arrête l'exécution du bloc
Si l'exception est du type spécifié dans except on exécute le bloc de cet except.
Variantes de except :
try:
...
except IOError:
# le code qui gère les exceptions de type `IOError`
...
except (TypeError, ValueError): # plusieurs types d'exceptions
...
except: # toutes les exceptions non encore gérées
...
else et le traitement des exceptions
else si aucune exception n'a été déclenchée
try:
x = 1
except:
print('erreur')
else:
print('ok')
as
as pour récupérer l'objet exception
>>> x = [6]
... try:
... x[2]
... except IndexError as exc:
... print('erreur index', exc)
...
('erreur index', IndexError('list index out of range',))
L'objet exc est une instance de la classe IndexError
raise
raise pour déclencher des exceptions
>>> raise NameError('HiThere')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: HiThere
Sans argument : re-déclenche la dernière exception gérée
>>> try:
... raise NameError('HiThere')
... except NameError:
... print('An exception flew by!')
... raise
...
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere
finally
finally pour exécuter un code qu'il y ait eu exception ou pas
Si une exception n'a pas été gérée, elle est déclenchée après finally
>>> x = [5]
>>> try:
... print(x[2])
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
IndexError: list index out of range
Exemple de traitement d'exceptions
>>> def divide(x, y):
... try:
... result = x / y
... except ZeroDivisionError:
... print("division by zero!")
... else:
... print("result is", result)
... finally:
... print("executing finally clause")
...
>>> divide(2, 1)
result is 2
executing finally clause
>>> divide(2, 0)
division by zero!
executing finally clause
>>> divide("2", "1")
executing finally clause
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "<stdin>", line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'
Espaces de noms
Permet de définir et d'utiliser le même nom dans des contextes différents
Variables globales / locales
>>> a, b = 1, 2 # définit deux variables dans l'espace de noms global
>>> def f():
... global b # la variable b est globale
... a = 3 # définit une variable a dans l'espace de noms
... # local de la fonction f
... b = 99
... print(a)
...
>>> f()
3
>>> a
1
>>> b
99
Exemple 1
x = 0
def f(x):
import Z
import X
from Y import A
for i in range(5):
j = 2 * i
définit les noms x, f, X, A, i, j dans l'espace de noms global ; x, Z dans l'espace de noms de f
NB : le nom Y n'est pas dans l'espace de noms
Exemple 2
A l'exécution, quand l'interpréteur rencontre un nom, il cherche dans l'espace de nom le plus proche, puis "remonte" jusqu'au niveau module puis aux noms intégrés de Python
a = 6
def f():
b = 8
def g(n):
print(n)
print(b)
print(a)
g(8)
Dans l'exécution de g :
- pas de nom
printdans les espaces locaux ni globaux, maisprintest un mot clé de Python - le nom
nest dans l'espace de noms de g - pas de nom
bdans l'espace de noms de g, on remonte jusqu'à l'espace de noms de f - pas de nom
adans l'espace de noms de g ni de f, on remonte jusqu'à l'espace de noms global
Bibliothèque standard
Bibliothèque standard : math
Fonctions mathématiques
>>> import math
>>> math.cos(math.pi / 4.0)
0.70710678118654757
>>> math.log(1024, 2)
10.0
Bibliothèque standard : random
Fonctions aléatoires
>>> import random
>>> random.choice(['apple', 'pear', 'banana'])
'apple'
>>> random.sample(xrange(100), 10) # sampling without replacement
[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]
>>> random.random() # random float
0.17970987693706186
>>> random.randrange(6) # random integer chosen from range(6)
4
Bibliothèque standard : datetime
Heures et dates
>>> import datetime
>>> now = datetime.date.today()
>>> now
datetime.date(2003, 12, 2)
>>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")
'12-02-03. 02 Dec 2003 is a Tuesday on the 02 day of December.'
>>> # dates support calendar arithmetic
>>> birthday = date(1964, 7, 31)
>>> age = now - birthday
>>> age.days
14368
>>> now = datetime.datetime.now() # heure locale (Paris - été)
>>> now
datetime.datetime(2015, 7, 1, 21, 15, 34, 874764)
>>> now = datetime.datetime.utcnow() # heure UTC
>>> now
datetime.datetime(2015, 7, 1, 19, 15, 34, 874764)
>>> now.year
2015
>>> now.month
7
>>> now.day
1
>>> now.hour
19
>>> now.minute
15
>>> now.second
34
>>> now.microsecond
874764
Attention aux notions de :
timezone(heure locale, heure UTC)! ( voir propriététzinfo)DSTdaylight saving time (changement d'heure été / hiver)
Un datetime peut être :
- timezone aware (possédant une timezone)
- timezone naïve (sans timezone associée
dt.tzinfoa la valeurNone)
On peut affecter une timezone via :
>>> import pytz
>>> now_tzaware = now.replace(tzinfo=pytz.UTC)
>>> now_tzaware
datetime.datetime(2015, 7, 1, 19, 15, 34, 874764, tzinfo=<UTC>)
Fonctions lambda
Exemple : fonctions anonymes
Fonctions anonymes, sur une seule ligne
>>> f = lambda x: 2*x
>>> f(4)
8
équivaut à
>>> def f(x):
... return 2*x
...
Les arguments sont passés sans parenthèse
Le corps de la fonction ne peut contenir qu'une instruction, son résultat est la valeur de retour
Peut être utile pour gagner quelques lignes - ne pas en abuser !
Exemple d'utilisation simple
>>> def make_incrementor(n):
... return lambda x: x + n
...
>>> f = make_incrementor(42)
>>> f(0)
42
>>> f(1)
43
équivaut à
def make_incrementor(n):
def g(x):
return x + n
return g
Exemple d'utilisation dans une interface graphique
Utilisation dans un GUI où la même fonction est utilisée pour gérer un clic sur une série de boutons
class Button:
def __init__(self):
self.events = {}
def bind(self, event, func):
self.events[event] = func
def click(self):
self.events['click']()
buttons = [Button() for i in range(10)]
def show(n):
"""Fonction qui gère l'événement clic sur un bouton"""
print('bouton %s' %n)
for i, button in enumerate(buttons):
button.bind('click', lambda x=i:show(x))
buttons[2].click()
Tri de liste t
Principe
t.sort(key=None, reverse=False)
trie la liste sur place (ne retourne pas la liste)
Si key n'est pas défini, utilise l'opérateur <
entre les éléments de la liste
>>> t = list('azerty')
>>> t.sort()
>>> t
['a', 'e', 'r', 't', 'y', 'z']
reverse=True pour inverser le tri
>>> t = list('azerty')
>>> t.sort(reverse=True)
>>> t
['z', 'y', 't', 'r', 'e', 'a']
Clé (key) pour le tri
t.sort(key=None, reverse=False)
Si keyest fourni, c'est une fonction qui prend 1 argument
Le tri compare les résultats de key(element) pour tous
les éléments de la liste
>>> t = list('AzeRty')
>>> t.sort()
>>> t
['A', 'R', 'e', 't', 'y', 'z']
Tri "insensible à la casse"
>>> t.sort(key=str.lower)
>>> t
['A', 'e', 'R', 't', 'y', 'z']
Tri d'une liste d'objets
class Z:
def __init__(self, nom, prenom):
self.nom = nom
self.prenom = prenom
def ident(self):
return '%s %s' %(self.prenom, self.nom)
def __repr__(self):
return '%s %s' %(self.nom, self.prenom)
presents = [Z('Bouchekif','Abdessalam'),
Z('Charlet','Delphine'),
Z('Geille','Christian')]
presents.sort(key=lambda x:x.ident())
print(presents)
Fichiers
Ouverture de fichier et mode d'ouverture
open(_filename,mode_)
Le mode peut être
- 'r' : lecture seule (valeur par défaut)
- 'a' : écriture en fin de fichier
- 'w' : effacement si le fichier existe déjà, puis écriture
Sur Windows, ajouter 'b' pour ouvrir les fichiers en mode binaire ('rb', 'wb'...)
Lecture
f.read(_nb_) pour lire au plus nb octets. Renvoie la chaîne vide '' en fin de fichier
f.read() pour lire tout le fichier
f.readline(): lit une ligne ; se termine par \n, ou '' en fin de fichier
f.readlines() lit toutes les lignes et les met dans un tableau
Itération sur les lignes :
for line in f:
...
Ecriture
f.write(_data_) pour écrire la chaîne data dans le fichier
>>> f.write('This is a test\n')
Pour écrire autre chose qu'une chaîne, il faut d'abord convertir en chaîne par str()
>>> f.write(42)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: expected a character buffer object
>>> out.write(str(42))
Autres méthodes
f.seek(_x_) positionne le pointeur à la position x
f.tell() renvoie la position courante du pointeur
f.close() ferme le fichier et libère les ressources associées
Utiliser de préférence with pour ne pas avoir à fermer explicitement
>>> with open('/tmp/workfile', 'r') as f:
... read_data = f.read()
>>> f.closed
True
Sérialisation :
pickle
Le module pickle permet de transformer en chaîne des objets complexes (listes, dictionnaires...) pour les stocker ou les envoyer sur le réseau
>>> import pickle
>>> pickle.dump(x, f) # écrit l'objet x dans le fichier f
>>> obj = pickle.load(f) # récupère l'objet x depuis le fichier f
Attention, il s'agit d'un format binaire qui n'est pas adapté pour une conservation à long terme.
JSON JavaScript Object Notation
Exemple de fichier JSON
{
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}
La documentation des méthodes loads (ou load pour un flux) et dumps est disponible sur
https://docs.python.org/3/library/json.html
XML
Extensible Markup Language
Exemple de fichier XML
<!DOCTYPE glossary PUBLIC "-//OASIS//DTD DocBook V3.1//EN">
<glossary><title>example glossary</title>
<GlossDiv><title>S</title>
<GlossList>
<GlossEntry ID="SGML" SortAs="SGML">
<GlossTerm>Standard Generalized Markup Language</GlossTerm>
<Acronym>SGML</Acronym>
<Abbrev>ISO 8879:1986</Abbrev>
<GlossDef>
<para>A meta-markup language, used to create markup
languages such as DocBook.</para>
<GlossSeeAlso OtherTerm="GML">
<GlossSeeAlso OtherTerm="XML">
</GlossDef>
<GlossSee OtherTerm="markup">
</GlossEntry>
</GlossList>
</GlossDiv>
</glossary>
Les fichiers XML sont composés de balises et d'attributs.
Parser un fichier XML peut être réalisé à l'aide au choix de :
- SAX
- DOM
- ElementTree
YAML
YAML Ain't Markup Language
Exemple de fichier YAML
---
glossary:
title: "example glossary"
GlossDiv:
title: "S"
GlossList:
GlossEntry:
ID: "SGML"
SortAs: "SGML"
GlossTerm: "Standard Generalized Markup Language"
Acronym: "SGML"
Abbrev: "ISO 8879:1986"
GlossDef:
para: "A meta-markup language, used to create markup languages such as DocBook."
GlossSeeAlso:
- "GML"
- "XML"
GlossSee: "markup"
La documentation des méthodes load et dump est disponible sur
http://pyyaml.org/wiki/PyYAMLDocumentation
import yaml
with open('fichier.yml', 'r') as fd:
dat = yaml.load(fd)
Autres techniques de sérialisation
- BSON
- MessagePack
- ...
Encodage, Unicode
Unicode est un standard qui associe à chaque lettre ou signe de toutes les écritures référencées un numéro de code unique noté U+abcd[e[f]]
| lettre | codepoint |
| U | U+0055 |
| Ж | U+0416 |
| ى | U+0649 |
| བྷ | U+0F57 |
Notion d'encodage
Les lettres ou signes doivent être transformés en octets pour être stockés sur disque ou envoyés sur les réseaux
La transformation se fait en utilisant un encodage
Il existe plusieurs encodages :
ascii: la lettre a (U+0061) est encodée sur 1 octet : 61 (hexa). Cet encodage ne traite que les caractères latins de base, les chiffres arabes et quelques signes de ponctuationlatin-1ouiso-8859-1: encodage sur 1 octet, prend en charge les caractères accentués françaisutf-8: encodage sur un nombre variable d'octets, prend en charge la plupart des caractères Unicode. Tend à devenir le plus répandu
Python 3, encode, decode
En Python 3 les "chaînes de caractères" (classe str) sont en Unicode
Leur transformation en octets se fait par la fonction encode(_encodage_)
>>> s = "maçon"
>>> s
'maçon'
>>> x = s.encode('utf-8')
>>> x
b'ma\xc3\xa7on'
Le résultat de encode est une instance de la classe bytes
Opération inverse : méthode decode(_encodage_)
>>> x.decode('utf-8')
'maçon'
Limitations des encodages 'ascii' et 'iso-8859-1'
Les encodages 'ascii' et 'iso-8859-1' ne peuvent pas traiter tous les caractères
>>> "maçon".encode("ascii")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\xe7' in position 2: o
rdinal not in range(128)
Stockage de chaîne de caractères dans des fichiers
Les fichiers stockent des octets, pas des caractères Unicode
Pour écrire une chaîne de caractères (Unicode) dans un fichier en mode texte, on peut spécifier l'encodage utilisé
>>> out = open('test.txt', 'w', encoding='utf-8')
>>> out.write('maçon')
5
Par défaut, l'encodage dépend de la plateforme.
Erreur d'encodage
Erreur si on ouvre un fichier en écriture avec un encodage donné et qu'on veut écrire un texte non supporté par cet encodage
>>> out = open('test.txt','w',encoding='ascii')
>>> out.write('maçon')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character '\xe7' in position 2: o
rdinal not in range(128)
Ouverture d'un fichier
Pour utiliser un fichier texte il faut spécifier son encodage
>>> _in = open('logs.txt', 'r', encoding='iso-8859-1')
>>> for line in _in:
... print(line)
Erreur si on n'utilise pas le bon encodage :
>>> out = open('test.txt','w',encoding='iso-8859-1')
>>> out.write('maçon')
5
>>> out.close()
>>> _in = open('test.txt','r',encoding='iso-8859-1')
>>> _in.read()
'maçon'
>>> _in = open('test.txt','r',encoding='utf-8')
>>> _in.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python33\lib\codecs.py", line 301, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe7 in position 2: invalid
continuation byte
Script et encodage
Si un script Python contient des caractères non ASCII, l'éditeur de texte l'enregistre sous un certain encodage
Il faut indiquer cet encodage à l'interpréteur Python qui exécute le script
Syntaxe : sur une des deux premières lignes
# -*- coding : utf-8 -*-